Introducción al estudio de la estructura social a partir de R
III Jornadas de Sociología - Universidad Nacional de Mar del Plata
3/15/23
Desventajas (2)
Desventajas (3)
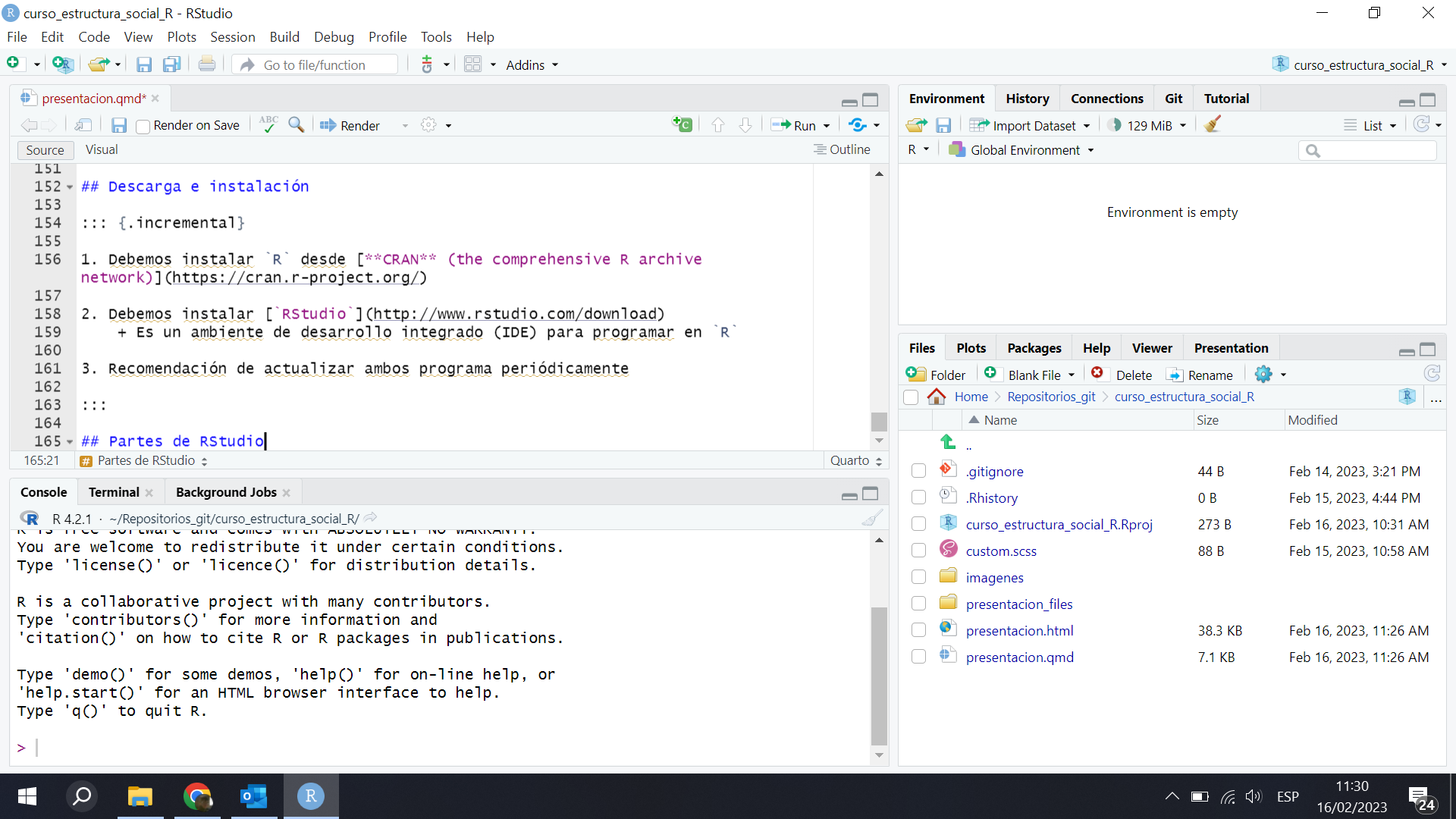
Partes de RStudio
Archivos del proyecto
Ambiente de trabajo
Consola
Script o sintaxis
¿Cómo hacer funcionar R?
Mediante
R base: comandos y funciones básicas que ya vienen incorporadas en el programaMediante paquetes:
- Conjunto de comandos y funciones elaborados por usuarios
- Facilitan el trabajo

Flujo de trabajo: Dinámica
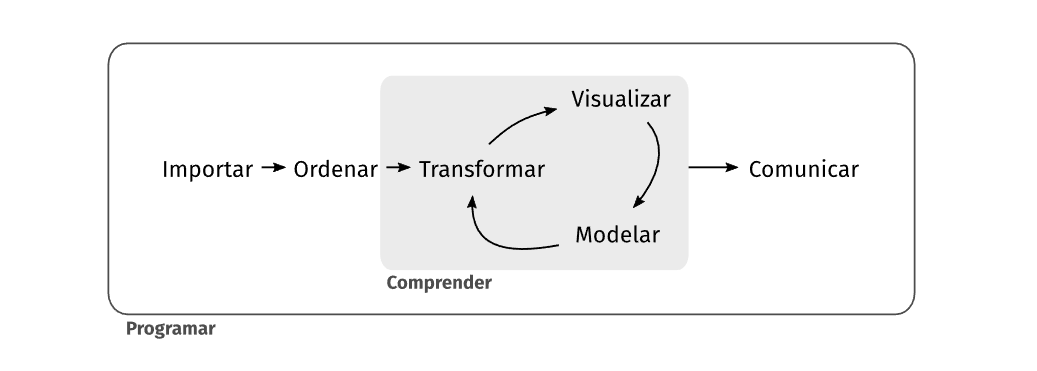
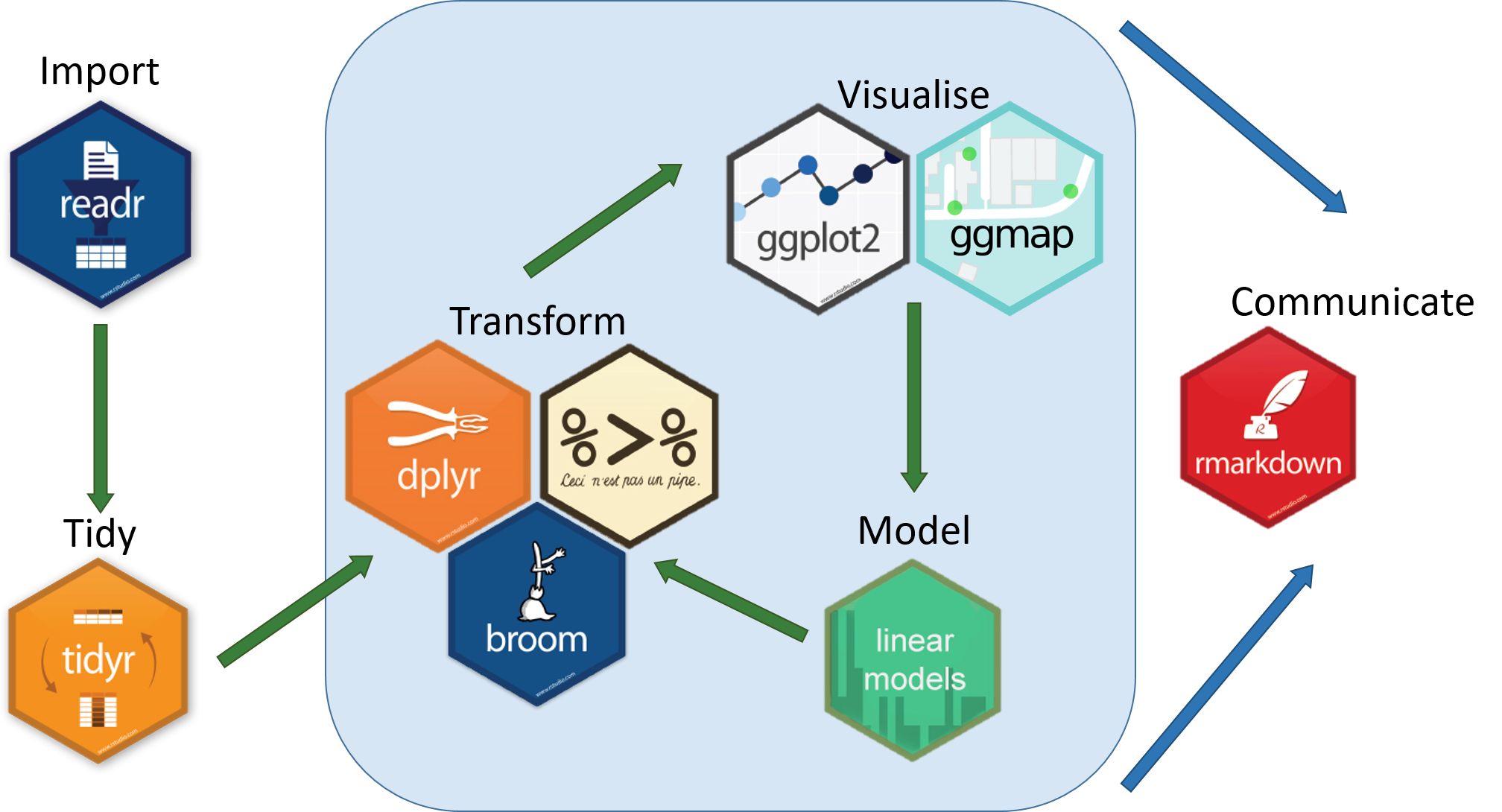
Flujo de trabajo: Proyectos
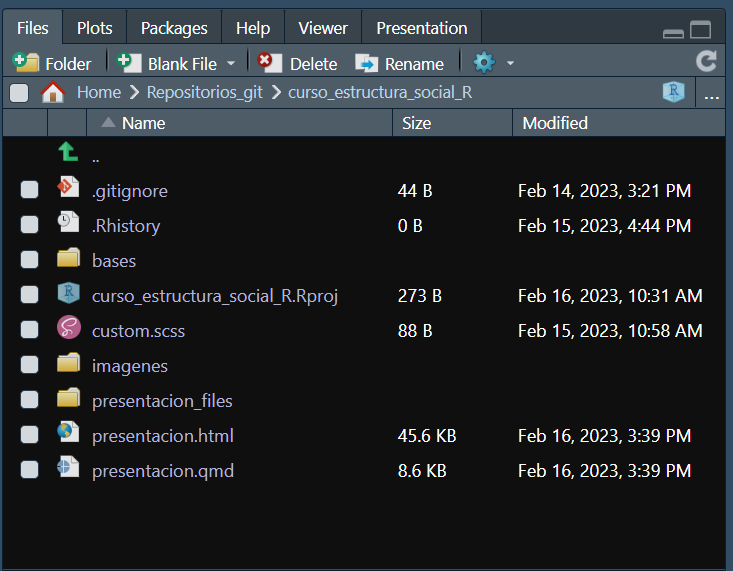
- Siempre es recomendable trabajar dentro de un proyecto
- Nos aseguraremos que todos los archivos y carpetas necesarios estén siempre en un lugar único
- Trabajaremos con rutas relativas.
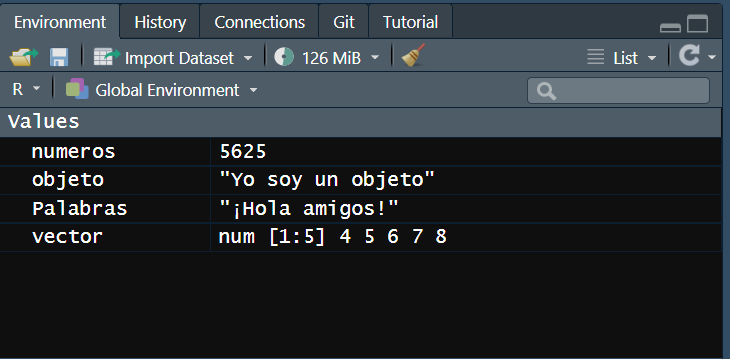
Flujo de trabajo: Objetos (1)
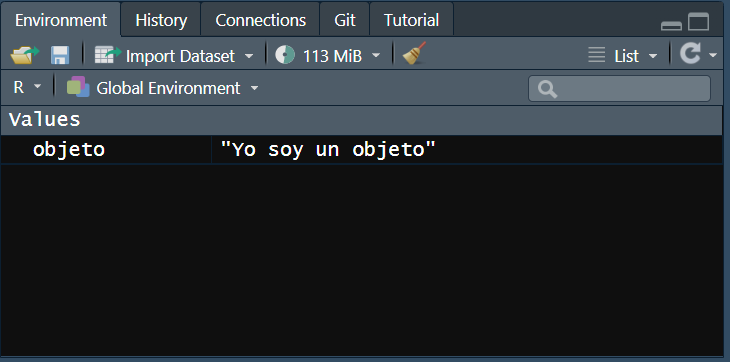
Todo lo que creemos en R es un objeto. Y en esto R es totalmente distinto a lo que conocíamos.
Flujo de trabajo: Objetos (2)
Podemos crear objetos a partir de:
Listas, data frames, gráficos, funciones, mapas y muchas cosas más.