install.packages("sjmisc")
install.packages("summarytools")
install.packages("janitor")
install.packages("openxlsx")
install.packages("flextable")
install.packages("DescTools")Clase 7 - Introducción al uso y aplicación de paquetes estadísticos para el tratamiento de fuentes de información en investigación social cuantitativa
1 Resumen y agregación de datos
Frecuentemente necesitamos resumir la información de alguna variable en un único valor. Por ejemplo, si queremos calcular el promedio de edad o de ingresos, o cualquier otra medida de tendencia central, lo que estamos haciendo es resumir la información de una variable en un único valor.
Otras veces, nuestra variable es de tipo categórica y queremos conocer la frecuencia de cada categoría en el total de la población. Es común, a partir de los datos censales, calcular tasas de actividad, de empleo, de analfabetismo, o razones masculinidad o femineidad, entre otras. En estos casos, previo al conteo de casos, necesitaremos agrupar a la población en las categorías de interés.
Para ello, en este apartado, revisaremos el uso de las funciones summarise() y group_by() del paquete dplyr para resumir y agregar datos.
1.1 Librerías
Para esta clase, necesitaremos tener instaladas las siguientes librerías:
1.2 Base de datos y librerías
Para revisar estas funciones utilizaremos la base del censo de personas. A su vez, seguiremos usando los paquetes del tidyverse.
library(tidyverse)
# Cargamos la base de datos
censo_personas <- readRDS("bases/censo10_personas.rds")1.3 Estadísticas resumen
El análisis exploratorio de datos funciona como una primera aproximación a las variables por separado. A la vez, nos sirve para observar si se cumplen determinados supuestos estadísticos.
Podemos clasificar cuatro tipos de estadísticas resumen: las de tendencia central, las de dispersión, las de forma y las de posición. Las primeras nos permiten resumir la información de una variable en un único valor, las segundas nos permiten conocer la variabilidad de los datos, las terceras nos permiten conocer la forma de la distribución de los datos y las últimas nos permiten identificar en que posición se ubican determinados valores de las variables.
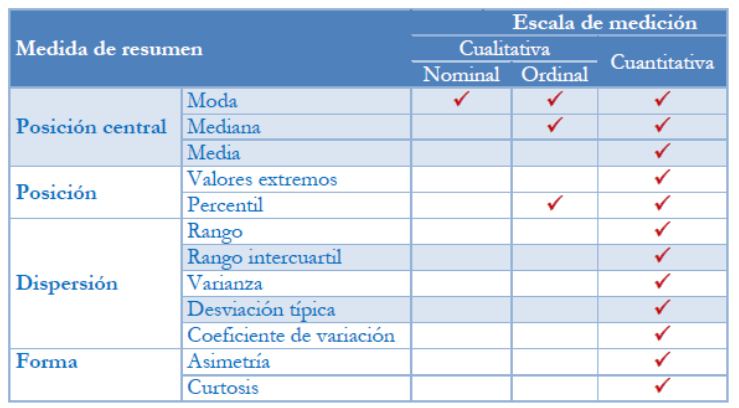
1.3.1 Medidas de tendencia central
Moda: valor más frecuente / puede realizarse en cualquier nivel de medición
Mediana: valor que determina la posición central de la distribución de la variable
- Es el valor que divide a la distribución en dos mitades (p50)
- Solo interviene el orden de las categorías de las variables. No se ve afectada por los valores extremos
- Puede calcularse en variables ordinales y cuantitativas
Media: promedio aritmético de todos los valores de la variable
- Solo aplicable en variables cuantitativas
- Es necesaria acompañarla de medidas de dispersión
- Puede calcularse también la media ponderada, recortada, geométrica o armónica
1.3.2 Medidas de posición
- Valores extremos: mínimo y máximo de una distribución de datos
- Cuantiles: nos proporcionan el valor de una variable que acumula un determinado número de casos.
- La mediana es el percentil 50
- Los cuantiles más conocidos son los cuartiles (25), quintiles (20) o deciles (10)
1.3.3 Medidas de dispersión
Complementan la información de centralidad, dan cuenta del comportamiento de la distribución y permiten observar cuán homogéneos o heterogéneos son los datos.
- Rango: diferencia entre el valor más grande y más pequeño de la distribución
- Rango intercuartil: diferencia entre el tercer cuartil (p75) y el primer cuartil (p25)
- Varianza: evalúa las distancias entre los valores particulares y el valor de la media
- Desvío estándar: es la raíz cuadrada de la varianza. Permite restituir la unidad de medida de la variable
- Coeficiente de variación: cociente entre desviación estándar y la media.
- Permite comparar entre distintas distribuciones.
- Se presenta en %
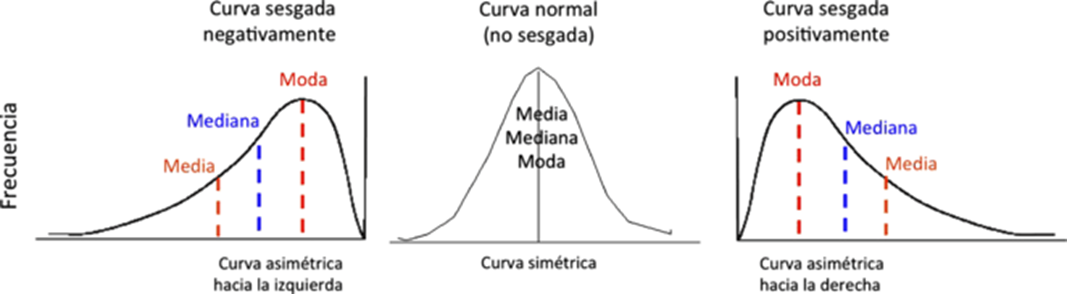
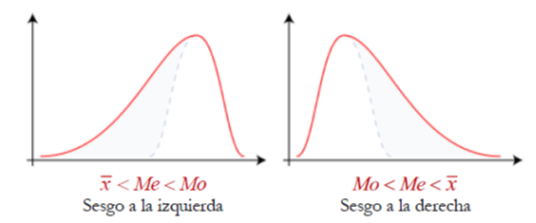
1.3.4 Medidas de forma
- Simetría: mide la simetría de la distribución de los datos
- Si es 0, la distribución es simétrica (curva normal)
- Si es positiva, la distribución es asimétrica hacia la derecha
- Si es negativa, la distribución es asimétrica hacia la izquierda
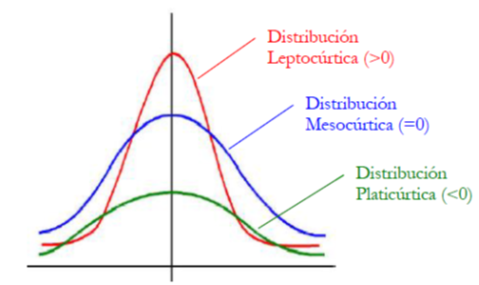
- Curtosis: permite observar el grado de apuntalamiento o achatamiento que presenta una distribución respecto a la distribución normal
- Si es 0, la distribución es mesocúrtica (curva normal)
- Si es positiva, la distribución es leptocúrtica (más puntiaguda)
- Si es negativa, la distribución es platicúrtica (más achatada)
1.3.5 Calculando medidas resumen en R
R base cuenta con una función que nos permite calcular estadísticas resumen de una variable de forma rápida y simple, la función summary(). Por ejemplo, si quisieramos estimar el promedio de edad de la población, y otrs estadísticos descriptivos, podríamos hacerlo de la siguiente forma:
summary(censo_personas$p03) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00 14.00 29.00 32.55 49.00 110.00 De este modo, observamos que la edad promedio es 32.55, la mediana es 29 y la edad máxima es 110.
En dplyr, la función summarise() nos permite realizar el mismo cálculo de forma más ordenada y clara. Por ejemplo, si quisiéramos calcular el promedio de edad de la población, podríamos hacerlo de la siguiente forma:
censo_personas %>%
summarise(promedio_edad = mean(p03))# A tibble: 1 × 1
promedio_edad
<dbl>
1 32.6summarise acepta toda una serie de estadísticos básicos que pueden utilizar:
mean(): promediomedian(): medianamin(): mínimomax(): máximosd(): desviación estándarvar(): varianzan(): número de observacionessum(): sumafirst(): primer valorlast(): último valorn_distinct(): número de valores distintos
censo_personas %>%
summarise(promedio_edad = mean(p03),
mediana_edad = median(p03),
min_edad = min(p03),
max_edad = max(p03),
sd_edad = sd(p03))# A tibble: 1 × 5
promedio_edad mediana_edad min_edad max_edad sd_edad
<dbl> <dbl> <dbl> <dbl> <dbl>
1 32.6 29 0 110 22.11.4 Agregación de datos
Otra forma de realizar resúmenes o cálculos sobre las variables es a partir de la información agrupada. Frecuentemente necesitamos que nuestras estadísticas sean calculadas por grupos de edad, sexo, nivel educativo, provincia de residencia, etc. Para ello, utilizamos la función group_by(), que como su nombre lo indica, nos agrupa la información en base a una variable. En términos de la matriz de datos, lo que hace es cambiar la unidad de análisis: de personas a grupos de edad, por ejemplo.
Si quisiéramos calcular el promedio de edad por sexo, podríamos seguir las siguientes instrucciones:
censo_personas %>%
group_by(p02) %>%
summarise(promedio_edad = mean(p03))# A tibble: 2 × 2
p02 promedio_edad
<dbl> <dbl>
1 1 31.3
2 2 33.7Fíjense que utilizando los pipes es sencillo encadenar cada una de las funciones. Primero agrupamos la información por sexo y luego calculamos el promedio de edad. Observando el libro de códigos, identificamos que 1 es varón y 2 mujer, y que el promedio de edad de los varones es 31.34 y de las mujeres es 33.7.
¿A qué se debe un promedio más alto en las mujeres? Una de las explicaciones es que la esperanza de vida de las mujeres es mayor que la de los varones. ¿Como podríamos estimar esto utilizando las funciones vistas anteriormente? Podríamos acercarnos calculando la edad máxima y el percentil 99 de cada sexo, es decir, el valor que acumula el 99% de las observaciones.
censo_personas %>%
group_by(p02) %>%
summarise(promedio_edad = mean(p03),
max_edad = max(p03),
percentil_99 = quantile(p03, 0.99))# A tibble: 2 × 4
p02 promedio_edad max_edad percentil_99
<dbl> <dbl> <dbl> <dbl>
1 1 31.3 110 82
2 2 33.7 110 861.4.1 Replicando algunos indicadores censales
Bajo el aplicativo REDATAM del Censo Nacional de Población, Hogares y Viviendas 2010, se pueden calcular una serie de indicadores censales ya predefinidos. Vamos a tratar de replicar algunos de estos para practicar el uso de group_by y summarise.
Relación de masculinidad: es el cociente entre la cantidad de varones y la cantidad de mujeres. Indica la cantidad de varones por cada cien mujeres en un área determinada.
censo_personas %>%
group_by(p02) %>% # Agrupamos por sexo
summarise(suma = n()) %>% # Contamos la cantidad de personas por sexo
summarise(relacion_masculinidad = (suma[p02 == 1] / suma[p02 == 2]) * 100) # Calculamos el cociente entre la cantidad de varones y mujeres y lo multiplicamos por 100.# A tibble: 1 × 1
relacion_masculinidad
<dbl>
1 94.8Fíjense que en este caso, utilizamos dos veces la función summarise(). La primera vez para contar la cantidad de personas por sexo y la segunda para calcular la relación de masculinidad. A su vez, se han utilizado los corchetes para filtrar la fila que debemos utilizar para el cálculo.
Índice de dependencia potencial: es el cociente entre la población potencialmente inactiva (grupos de 0 a 14 y 65 años y más) y la población en edades “teóricamente” activas (15 a 64 años).
Vamos a aprovechar el uso de la variable construida EDADAGRU que nos permite identificar a las personas en grupos de edad (0-14 / 15-64 / 65 y más). Es una variable similar a la que construimos en la clase anterior.
censo_personas %>%
group_by(edadagru) %>% # Agrupamos por grupo de edad
summarise(suma = n()) %>% # Contamos la cantidad de personas por grupo de edad
summarise(indice_dependencia = (suma[edadagru == 1] + suma[edadagru == 3]) / suma[edadagru == 2] * 100) # Calculamos el cociente entre la población potencialmente inactiva y la población en edades activas.# A tibble: 1 × 1
indice_dependencia
<dbl>
1 55.6Tasa de desocupación: es el porcentaje entre la población desocupada y la población económicamente activa. Brinda información sobre la proporción de personas que están demandando trabajo y no lo consiguen.
Vamos a calcular esta tasa pero a nivel provincial, es decir, vamos a agregar la información por por dos variables: provincia (provincia de residencia) y condact (condición de actividad). Para obtener las etiquetas de las provincias, primero construiremos una variable de tipo factor.
censo_personas <- censo_personas %>%
mutate(provincia_f = factor(provincia, labels = c("CABA",
"Buenos Aires",
"Catamarca",
"Córdoba",
"Corrientes",
"Chaco",
"Chubut",
"Entre Ríos",
"Formosa",
"Jujuy",
"La Pampa",
"La Rioja",
"Mendoza",
"Misiones",
"Neuquén",
"Río Negro",
"Salta",
"San Juan",
"San Luis",
"Santa Cruz",
"Santa Fe",
"Santiago del Estero",
"Tucumán",
"Tierra del Fuego, Antártida e Islas del Atlántico Sur")))
censo_personas %>%
filter(condact != 0) %>% # quitamos los casos que no aplican a la variable condición de actividad
group_by(provincia_f, condact) %>% # agrupamos los casos por provincia y condición de actividad
summarise(suma = n()) %>% # sumamos los casos
group_by(provincia_f) %>% # ahora agrupamos solo por provincia
summarise(tasa_desocupacion = (suma[condact == 2] / (suma[condact == 1] + suma[condact == 2])) * 100) %>% # calculamos la tasa de desocupación
arrange(-tasa_desocupacion) # ordenamos de mayor a menor tasa de desocupación`summarise()` has grouped output by 'provincia_f'. You can override using the
`.groups` argument.# A tibble: 24 × 2
provincia_f tasa_desocupacion
<fct> <dbl>
1 Tucumán 7.89
2 San Juan 7.81
3 Salta 7.63
4 San Luis 7.20
5 Catamarca 7.10
6 Mendoza 6.94
7 Neuquén 6.29
8 Río Negro 6.26
9 Santiago del Estero 6.20
10 La Rioja 6.13
# ℹ 14 more rowsPara hacer este último cálculo hemos realizado más pasos que en los anteriores. Primero, hemos filtrado los casos que no aplican a la variable condact (0 = no aplica, 1 = ocupado, 2 = desocupado, 3 = inactivo). Luego, hemos agrupado por provincia y condición de actividad, sumando los casos. Posteriormente, hemos vuelto a agrupar solo por provincia y calculado la tasa de desocupación. Finalmente, hemos ordenado de mayor a menor tasa de desocupación.
2 Construcción de tablas
En esta apartado revisaremos distintas aproximaciones a la construcción de tablas de frecuencias y de tablas de contingencia. Quizás R no se destaque por la simpleza del análisis exploratorio a través de tablas, pero existen infinidad de paquetes que nos permitirán llegar a resultados similares. Empezaremos explorando la funciones disponibles en R base, luego revisaremos algunos paquetes que harán la mayor parte del trabajo por nosotros y, por último, veremos cómo podemos hacerlo con dplyr y tidyr de tidyverse.
2.1 La función table()
La función table() es una de las más utilizadas para la construcción de tablas de frecuencias, tanto para el análisis univariable como bivariable. Para esta sección, a los fines agilizar el proceso de trabajo, vamos a seleccionar trabajar con los casos de la provincia de Mendoza, creando el objeto censo_personas_mendoza.
censo_personas_mendoza <- censo_personas %>%
filter(provincia == 50)Ahora vamos a identificar a las variables educativas nivel educativo que cursa o cursó (p09) y completó ese nivel (p10) y vamos a convertirlas a factores.
censo_personas_mendoza <- censo_personas_mendoza %>%
mutate(p09 = factor(p09, labels = c("No aplica",
"Inicial",
"Primario",
"EGB",
"Secundario",
"Polimodal",
"Sup. no universitario",
"Universitario",
"Posgrado",
"Educación especial")),
p10 = factor(p10, labels = c("No aplica",
"Completó",
"No completó")))Ahora si, con la función table() vamos a construir una tabla de frecuencias de la variable p09. Como se verá, la salida es rápida pero con información escueta: no tenemos frecuencias relativas, ni acumuladas.
table(censo_personas_mendoza$p09)
No aplica Inicial Primario
155868 65713 599179
EGB Secundario Polimodal
133561 388181 92638
Sup. no universitario Universitario Posgrado
106945 180004 9049
Educación especial
7791 Si queremos calcular las proporciones o frecuencias relativas, podemos llamar a la función prop.table() sobre la función ya especificada:
prop.table(table(censo_personas_mendoza$p09))
No aplica Inicial Primario
0.089634482 0.037789352 0.344567835
EGB Secundario Polimodal
0.076806471 0.223229931 0.053273020
Sup. no universitario Universitario Posgrado
0.061500498 0.103514290 0.005203778
Educación especial
0.004480344 Por último, si queremos presentar los resultados en porcentajes, lo multiplicamos por 100:
prop.table(table(censo_personas_mendoza$p09)) * 100
No aplica Inicial Primario
8.9634482 3.7789352 34.4567835
EGB Secundario Polimodal
7.6806471 22.3229931 5.3273020
Sup. no universitario Universitario Posgrado
6.1500498 10.3514290 0.5203778
Educación especial
0.4480344 Estas funciones nos sirven también para tablas cruzadas. Por ejemplo calculemos el nivel educativo de las personas según si han completado o no ese nivel.
table(censo_personas_mendoza$p09, censo_personas_mendoza$p10)
No aplica Completó No completó
No aplica 155868 0 0
Inicial 65713 0 0
Primario 0 285394 313785
EGB 0 8965 124596
Secundario 0 182652 205529
Polimodal 0 14262 78376
Sup. no universitario 0 60409 46536
Universitario 0 74737 105267
Posgrado 0 5916 3133
Educación especial 7791 0 0Y si quisiéramos calcular los porcentajes por fila…
prop.table(table(censo_personas_mendoza$p09, censo_personas_mendoza$p10), margin = 1) * 100
No aplica Completó No completó
No aplica 100.000000 0.000000 0.000000
Inicial 100.000000 0.000000 0.000000
Primario 0.000000 47.630842 52.369158
EGB 0.000000 6.712289 93.287711
Secundario 0.000000 47.053308 52.946692
Polimodal 0.000000 15.395410 84.604590
Sup. no universitario 0.000000 56.486044 43.513956
Universitario 0.000000 41.519633 58.480367
Posgrado 0.000000 65.377390 34.622610
Educación especial 100.000000 0.000000 0.000000Como verán, la función table() es muy útil para la construcción rápida de tablas de frecuencias, pero no nos permite realizar análisis complementarios, ni nos otorgan una salida en formato tidy.
2.2 Algunas librerías para la construcción de tablas
A veces necesitamos hacer procesamientos rápidos, sin necesidad de escribir mucho código. Si nuestra opción es quedarnos usando R y no migrar a otros programas, podemos utilizar algunas librerías que nos facilitarán la construcción de tablas. Les dejamos una lista con la variedad de librerías que pueden utilizar:
janitorexpsssummarytoolsgmodelssjmisc
Vamos a realizar una primera prueba utilizando la librería sjmisc. En primer lugar, la función frq() nos devuelve una tabla de frecuencias algo más completa que la función table().
library(sjmisc)
censo_personas_mendoza %>%
frq(p09)p09 <categorical>
# total N=1738929 valid N=1738929 mean=4.29 sd=2.04
Value | N | Raw % | Valid % | Cum. %
---------------------------------------------------------
No aplica | 155868 | 8.96 | 8.96 | 8.96
Inicial | 65713 | 3.78 | 3.78 | 12.74
Primario | 599179 | 34.46 | 34.46 | 47.20
EGB | 133561 | 7.68 | 7.68 | 54.88
Secundario | 388181 | 22.32 | 22.32 | 77.20
Polimodal | 92638 | 5.33 | 5.33 | 82.53
Sup. no universitario | 106945 | 6.15 | 6.15 | 88.68
Universitario | 180004 | 10.35 | 10.35 | 99.03
Posgrado | 9049 | 0.52 | 0.52 | 99.55
Educación especial | 7791 | 0.45 | 0.45 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>El mismo paquete nos permite realizar tablas cruzadas con la función flat_table.
censo_personas_mendoza %>%
flat_table(p09, p10, margin = "row") p10 No aplica Completó No completó
p09
No aplica 100.00 0.00 0.00
Inicial 100.00 0.00 0.00
Primario 0.00 47.63 52.37
EGB 0.00 6.71 93.29
Secundario 0.00 47.05 52.95
Polimodal 0.00 15.40 84.60
Sup. no universitario 0.00 56.49 43.51
Universitario 0.00 41.52 58.48
Posgrado 0.00 65.38 34.62
Educación especial 100.00 0.00 0.00summarytools es otra librería que nos permite realizar tablas de frecuencias. En este caso, la función freq() nos devuelve una tabla de frecuencias similar a la función anterior.
library(summarytools)
censo_personas_mendoza %>%
freq(p09)Frequencies
censo_personas_mendoza$p09
Type: Factor
Freq % Valid % Valid Cum. % Total % Total Cum.
--------------------------- --------- --------- -------------- --------- --------------
No aplica 155868 8.96 8.96 8.96 8.96
Inicial 65713 3.78 12.74 3.78 12.74
Primario 599179 34.46 47.20 34.46 47.20
EGB 133561 7.68 54.88 7.68 54.88
Secundario 388181 22.32 77.20 22.32 77.20
Polimodal 92638 5.33 82.53 5.33 82.53
Sup. no universitario 106945 6.15 88.68 6.15 88.68
Universitario 180004 10.35 99.03 10.35 99.03
Posgrado 9049 0.52 99.55 0.52 99.55
Educación especial 7791 0.45 100.00 0.45 100.00
<NA> 0 0.00 100.00
Total 1738929 100.00 100.00 100.00 100.00Del mismo modo, la función ctable() realiza el cruce entre ambas variables, pudiendo elegir calcular las proporciones por fila, columna o total con la opción prop. El problema es que esta función no funciona con el pipe %>%.
ctable(censo_personas_mendoza$p09, censo_personas_mendoza$p10, prop = "r")Cross-Tabulation, Row Proportions
p09 * p10
Data Frame: censo_personas_mendoza
----------------------- ----- ----------------- ---------------- ---------------- ------------------
p10 No aplica Completó No completó Total
p09
No aplica 155868 (100.0%) 0 ( 0.0%) 0 ( 0.0%) 155868 (100.0%)
Inicial 65713 (100.0%) 0 ( 0.0%) 0 ( 0.0%) 65713 (100.0%)
Primario 0 ( 0.0%) 285394 (47.6%) 313785 (52.4%) 599179 (100.0%)
EGB 0 ( 0.0%) 8965 ( 6.7%) 124596 (93.3%) 133561 (100.0%)
Secundario 0 ( 0.0%) 182652 (47.1%) 205529 (52.9%) 388181 (100.0%)
Polimodal 0 ( 0.0%) 14262 (15.4%) 78376 (84.6%) 92638 (100.0%)
Sup. no universitario 0 ( 0.0%) 60409 (56.5%) 46536 (43.5%) 106945 (100.0%)
Universitario 0 ( 0.0%) 74737 (41.5%) 105267 (58.5%) 180004 (100.0%)
Posgrado 0 ( 0.0%) 5916 (65.4%) 3133 (34.6%) 9049 (100.0%)
Educación especial 7791 (100.0%) 0 ( 0.0%) 0 ( 0.0%) 7791 (100.0%)
Total 229372 ( 13.2%) 632335 (36.4%) 877222 (50.4%) 1738929 (100.0%)
----------------------- ----- ----------------- ---------------- ---------------- ------------------2.3 Tablas con dplyr y tidyr
Si bien las librerías anteriores nos permiten realizar tablas de frecuencias de forma rápida y sencilla, no siguen la filosofía del tidyverse que venimos utilizando y que nos servirá para trabajar en forma ordenada en cada momento de la investigación. Quizás, a principio, la elaboración de tablas con estás funciones sea algo complicado, pero a futuro nos facilitará la posterior presentación de los resultados en documentos o en gráficos.
La secuencia de pasos es similar a como lo hemos hecho en el apartado de la sección 1.4. Primero agrupamos la información (group_by()) y luego contamos los casos. Recuerden que esto último podemos hacerlo mediante la función summarise(), count() o tally().
censo_personas_mendoza %>%
group_by(p09) %>%
summarise(frecuencia = n())# A tibble: 10 × 2
p09 frecuencia
<fct> <int>
1 No aplica 155868
2 Inicial 65713
3 Primario 599179
4 EGB 133561
5 Secundario 388181
6 Polimodal 92638
7 Sup. no universitario 106945
8 Universitario 180004
9 Posgrado 9049
10 Educación especial 7791censo_personas_mendoza %>%
group_by(p09) %>%
count()# A tibble: 10 × 2
# Groups: p09 [10]
p09 n
<fct> <int>
1 No aplica 155868
2 Inicial 65713
3 Primario 599179
4 EGB 133561
5 Secundario 388181
6 Polimodal 92638
7 Sup. no universitario 106945
8 Universitario 180004
9 Posgrado 9049
10 Educación especial 7791censo_personas_mendoza %>%
group_by(p09) %>%
tally()# A tibble: 10 × 2
p09 n
<fct> <int>
1 No aplica 155868
2 Inicial 65713
3 Primario 599179
4 EGB 133561
5 Secundario 388181
6 Polimodal 92638
7 Sup. no universitario 106945
8 Universitario 180004
9 Posgrado 9049
10 Educación especial 7791Para realizar tablas bivariadas, lo primero que adicionaremos es la segunda variable a la función group_by(). Luego, contaremos los casos con cualquiera de la funciones de conteo.
censo_personas_mendoza %>%
group_by(p09, p10) %>%
tally()# A tibble: 17 × 3
# Groups: p09 [10]
p09 p10 n
<fct> <fct> <int>
1 No aplica No aplica 155868
2 Inicial No aplica 65713
3 Primario Completó 285394
4 Primario No completó 313785
5 EGB Completó 8965
6 EGB No completó 124596
7 Secundario Completó 182652
8 Secundario No completó 205529
9 Polimodal Completó 14262
10 Polimodal No completó 78376
11 Sup. no universitario Completó 60409
12 Sup. no universitario No completó 46536
13 Universitario Completó 74737
14 Universitario No completó 105267
15 Posgrado Completó 5916
16 Posgrado No completó 3133
17 Educación especial No aplica 7791Como verán, la tabla se nos presenta en un formato extraño, que se denomina long o largo, debido a que las dos variables de interés se sitúan en las primeras columnas y las frecuencias en la última. En algunos casos, como por ejemplo para la construcción de gráficos, este formato es apropiado. Pero para la presentación de tablas, necesitamos un formato de tipo wide o ancho.
Para presentar la tabla en un formato más amigable, utilizaremos la función pivot_wider de tidyr. Lo que debemos declarar en dicha función es cual es la variable que pasará a mostrar sus categorías en las columnas y de dónde surgirán los valores que irán en las celdas. En nuestro caso, las columnas se completarán con las categorías de la variable p10 y los valores serán las frecuencias de los conteos de la variable n que construimos en el paso anterior.
censo_personas_mendoza %>%
group_by(p09, p10) %>%
tally() %>%
pivot_wider(names_from = p10, values_from = n)# A tibble: 10 × 4
# Groups: p09 [10]
p09 `No aplica` Completó `No completó`
<fct> <int> <int> <int>
1 No aplica 155868 NA NA
2 Inicial 65713 NA NA
3 Primario NA 285394 313785
4 EGB NA 8965 124596
5 Secundario NA 182652 205529
6 Polimodal NA 14262 78376
7 Sup. no universitario NA 60409 46536
8 Universitario NA 74737 105267
9 Posgrado NA 5916 3133
10 Educación especial 7791 NA NAVamos a seguir emprolijando la tabla, eliminando los casos de la variable p10 que son no aplica.
censo_personas_mendoza %>%
filter(p10 != "No aplica") %>%
group_by(p09, p10) %>%
tally() %>%
pivot_wider(names_from = p10, values_from = n)# A tibble: 7 × 3
# Groups: p09 [7]
p09 Completó `No completó`
<fct> <int> <int>
1 Primario 285394 313785
2 EGB 8965 124596
3 Secundario 182652 205529
4 Polimodal 14262 78376
5 Sup. no universitario 60409 46536
6 Universitario 74737 105267
7 Posgrado 5916 3133Como se vera, la tabla se presenta de forma más ordenada y clara, sin embargo, aún no hemos calculado las proporciones. Para ello, lo mejor es valerse de la librería janitor que automáticamente nos calculará distintos tipos de proporciones, nos presentará los datos en formato porcentual y nos dejará agregar los totales por fila o columna. Exploremos la librería.
library(janitor)
censo_personas_mendoza %>%
filter(p10 != "No aplica") %>%
group_by(p09, p10) %>%
tally() %>%
pivot_wider(names_from = p10, values_from = n) %>%
adorn_totals("row") %>% # Agregamos los totales por fila
adorn_percentages("row") %>% # Calculamos las proporciones por fila
adorn_pct_formatting(digits = 1) # Presentamos los valores en formato porcentual p09 Completó No completó
Primario 47.6% 52.4%
EGB 6.7% 93.3%
Secundario 47.1% 52.9%
Polimodal 15.4% 84.6%
Sup. no universitario 56.5% 43.5%
Universitario 41.5% 58.5%
Posgrado 65.4% 34.6%
Total 41.9% 58.1%2.3.1 El formato tidy
Disponer los datos en forma ordenada implica que: 1) cada variable es una columna, 2) cada observación es una fila y 3) cada valor se encuentra en una celda. Sin embargo muchas veces, los datos distan de presentarse en ficho formato. Por ejemplo, es frecuente que:
- los encabezados de las columnas sean valores,
- muchas variables sean guardadas en una columna,
- las variables se encuentren en las filas y columnas,
- múltiples unidades de análisis se encuentren en una misma tabla,
- una unidad de análisis se encuentre en varias tablas.
Para resolver estos problemas, tidyr nos ofrece las funciones pivot_longer() y pivot_wider(). La primera nos permite pasar de un formato ancho a uno largo, mientras que la segunda nos permite pasar de un formato largo a uno ancho.
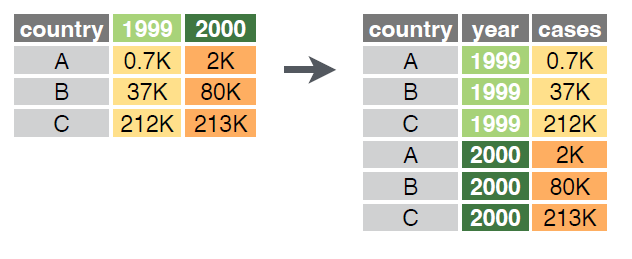
pivot_longer() nos permite pasar de un formato ancho a uno largo. Para ello, debemos especificar las columnas que queremos mantener y las que queremos transformar en filas. Con la función names_to especificamos el nombre de la nueva columna que contendrá los nombres de las columnas que estamos transformando en filas, y con values_to especificamos el nombre de la nueva columna que contendrá los valores de las columnas que estamos transformando en filas.
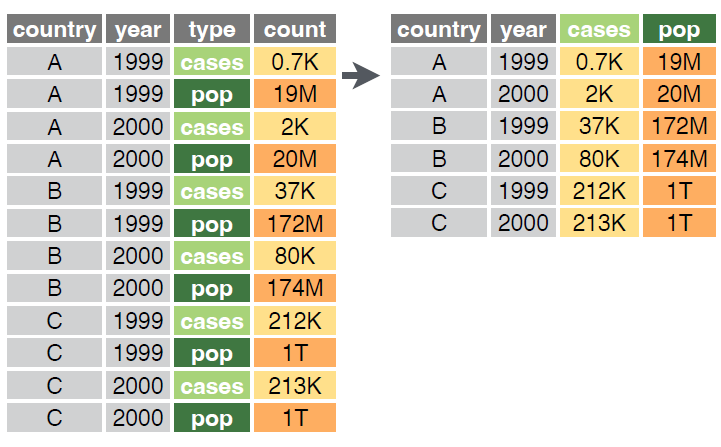
pivot_wider() nos permite pasar de un formato largo a uno ancho. Para ello, debemos especificar las columnas que queremos mantener y las que queremos transformar en columnas. Con la función names_from especificamos el nombre de la nueva columna que contendrá los nombres de las columnas que estamos transformando en columnas, y con values_from especificamos el nombre de la nueva columna que contendrá los valores de las columnas que estamos transformando en columnas.
2.4 Medidas de asociación
Las medidas de asociación son estadísticos que nos permiten evaluar la relación entre dos variables. En el caso de las tablas de contingencia, las medidas de asociación nos permiten evaluar si existe una relación entre las variables y, en caso de existir, cuál es la fuerza y dirección de esa relación (en el caso de variables ordinales).
Existen muchas medidas de asociación, pero aquí señalaremos algunas de las más comunes y frecuentemente utilizadas:
Chi-cuadrado de Pearson: es una medida de asociación que nos permite evaluar si existe una relación entre dos variables categóricas. La hipótesis nula es que no existe relación entre las variables. Si el valor de chi-cuadrado es significativo, rechazamos la hipótesis nula y concluimos que existe una relación entre las variables. Su mínimo es 0 y su máximo es infinito. No mide la fuerza de la asociación.
V de Cramer: está basada en la prueba de Chi cuadrado y está pensada para variables nominales. Permite determinar la fuerza de la asociación. Su valor oscila entre 0 y 1. A mayor valor, mayor es la fuerza de la asociación.
Tau de Kendall: es una medida de asociación no paramétrica que mide la asociación entre dos variables ordinales. Su valor oscila entre -1 y 1. Valores positivos indican una asociación directa, valores negativos una asociación inversa y 0 la ausencia de asociación.
Residuos: los residuos son una medida de asociación que nos permite identificar en qué celdas de la tabla de contingencia se concentra la asociación. Los residuos positivos indican que la frecuencia observada es mayor que la esperada, mientras que los residuos negativos indican que la frecuencia observada es menor que la esperada.
Vamos a calcular el chi-cuadrado de Pearson y la V de Cramer para evaluar la asociación existente entre el nivel educativo alcanzado (p09) y la utilización de computadora (p12). Para ello, utilizaremos la función chisq.test() de R base y la función CramerV de la librería DescTools.
library(DescTools)
#Creamos un nuevo objeto sin los casos que no aplican en p12
censo_personas_mendoza2 <- censo_personas_mendoza %>%
filter(p12 != 0)
# Calculamos el chi-cuadrado de Pearson
chisq.test(censo_personas_mendoza2$p09, censo_personas_mendoza2$p12)
Pearson's Chi-squared test
data: censo_personas_mendoza2$p09 and censo_personas_mendoza2$p12
X-squared = 405231, df = 9, p-value < 2.2e-16# Calculamos otros coeficientes
CramerV(censo_personas_mendoza2$p09, censo_personas_mendoza2$p12)[1] 0.4989567El resultado del chi-cuadrado de Pearson nos indica que existe una relación significativa entre las variables, ya que el valor de p es menor a 0.05. Por otro lado, la V de Cramer nos indica que la fuerza de la asociación es alta, ya que el valor es 0.499, es decir, el nivel educativo alcanzado influencia, como es esperado, el uso o no de computadoras.
3 Exportando los resultados
Hasta aquí hemos trabajado con tablas de frecuencias y con tablas de contingencia. Si lo que necesitamos es explorar los datos para conocer la información que disponemos, probar hipótesis o realizar análisis descriptivos, con las salidas gráficas que nos ofrece RStudio nos bastaría. Sin embargo, a veces, necesitamos presentar los resultados en informes, documentos o presentaciones. Para ello, necesitamos exportar los resultados a formatos comúnmente como xlsx, docx, pdf, etc.
En esta sección vamos a mostrar algunas alternativas para exportar los resultados a una hoja de calculo (xlsx) y a un documento de texto (docx). No obstante, existen muchas otras opciones de exportación que pueden explorarse y que se complementan muy bien con el análisis estadístico en RStudio, tales como html o pdf.
Recomendación
A lxs interesadxs les recomendamos revisar los sistemas de publicación científica tales como RMarkdown y Quarto. Ambos sistemas permiten la integración de código R con texto, gráficos y tablas, y la exportación a distintos formatos de salida.
3.1 Exportando a xslx
Para exportar los resultados a una hoja de cálculo, utilizaremos la librería openxlsx. Esta librería nos permite exportar los resultados a un archivo de Excel, añadir hojas de calculo, modificar el formato de las celdas, entre otras cosas. Vamos a revisar las funciones más sencillas del paquete. Para ello, crearemos un objeto con la tabla cruzada que creamos en la sección anterior.
library(openxlsx)
# Creamos un objeto con la tabla de frecuencias
tabla_educ <- censo_personas_mendoza %>%
filter(p10 != "No aplica") %>%
group_by(p09, p10) %>%
tally() %>%
pivot_wider(names_from = p10, values_from = n) %>%
adorn_totals("row") %>%
adorn_percentages("row") %>%
adorn_pct_formatting(digits = 1)
# Exportamos la tabla a un archivo de Excel
write.xlsx(tabla_educ, "resultados/tabla_educ.xlsx")El resultado de la función write.xlsx fue la creación de un archivo en la carpeta resultados con el nombre tabla_educ.xlsx. Si abrimos el archivo, veremos que la tabla se ha exportado correctamente.
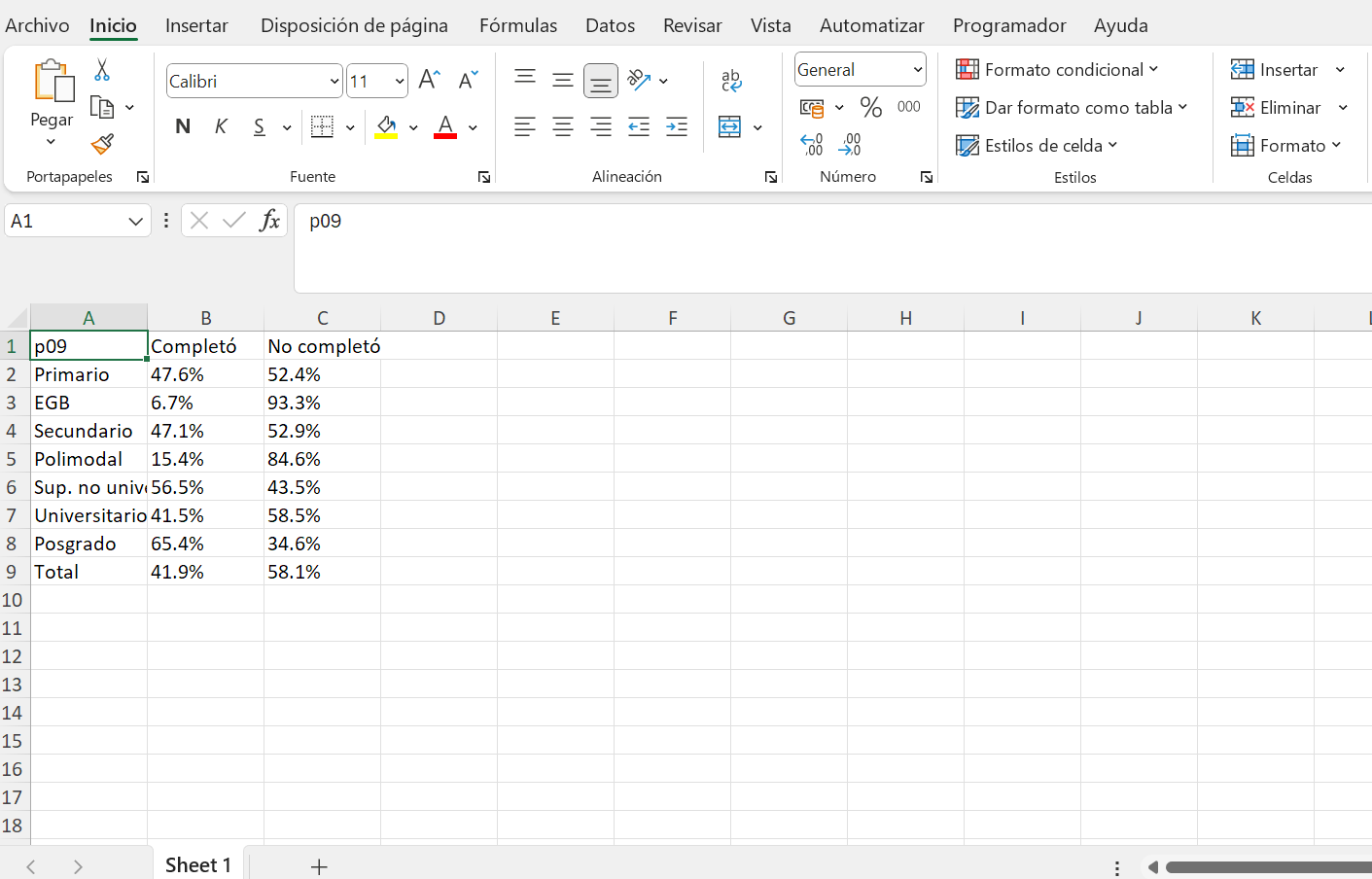
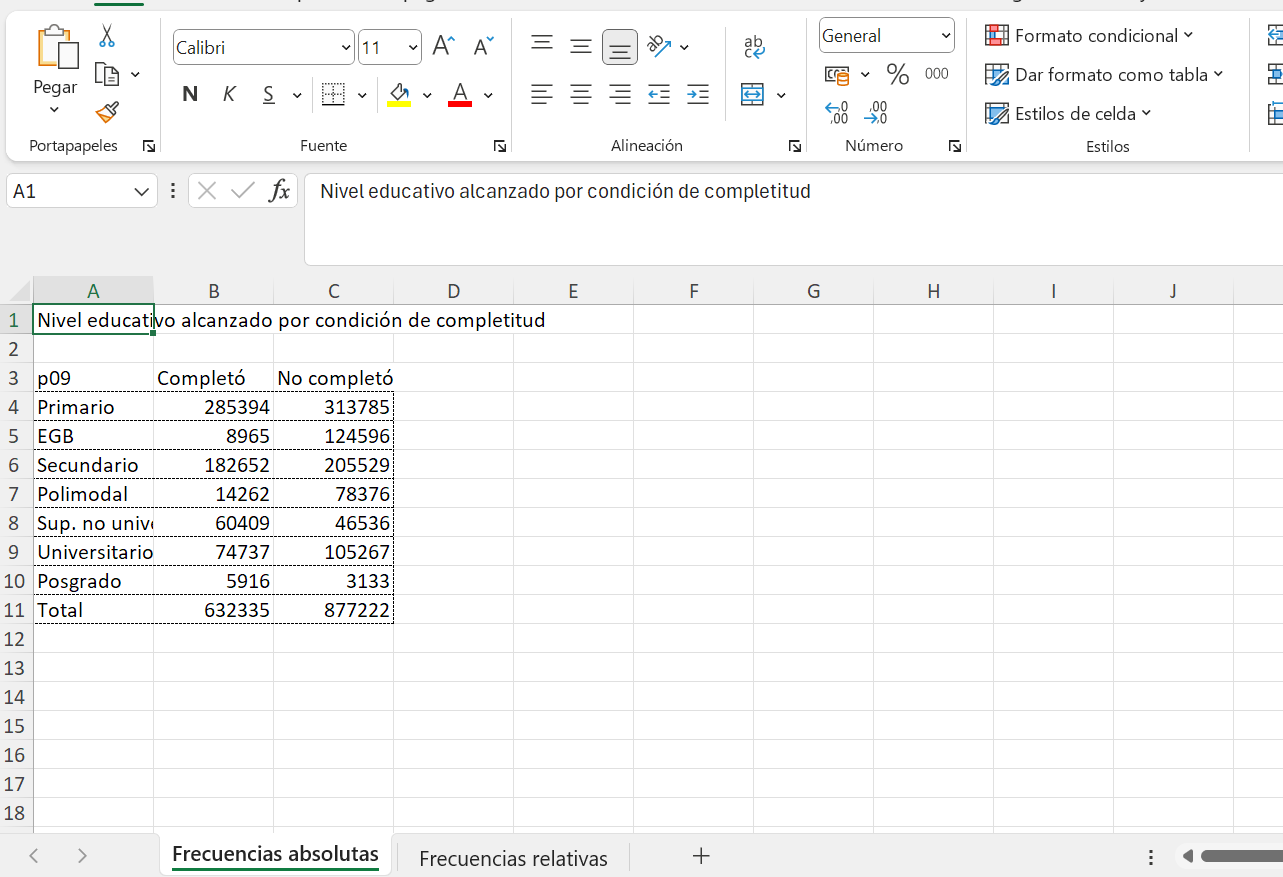
Ahora bien, si dentro de nuestro flujo de trabajo construimos varias tablas y queremos exportarlas a un único archivo, podemos hacerlo creando un workbook con la función createWorkbook() y luego añadiendo las tablas con la función addWorksheet(). Veamos paso a paso cómo hacerlo. En la primera hoja pondremos la tabla pero con las frecuencias absolutas y en la segunda hoja el objeto tabla_educ que creamos anteriormente.
# Creamos un objeto con la tabla de frecuencias absolutas
tabla_educ_simple <- censo_personas_mendoza %>%
filter(p10 != "No aplica") %>%
group_by(p09, p10) %>%
tally() %>%
pivot_wider(names_from = p10, values_from = n) %>%
adorn_totals("row")
# Creamos un workbook
wb <- createWorkbook()
# Añadimos la primera hoja
addWorksheet(wb, sheetName = "Frecuencias absolutas")
# Escribimos la tabla en la primera hoja
writeData(wb, sheet = "Frecuencias absolutas", x = "Nivel educativo alcanzado por condición de completitud", startRow = 1)
writeData(wb, sheet = "Frecuencias absolutas", x = tabla_educ_simple,
borders = "rows" , borderStyle = "dashed", startRow = 3)
# Añadimos la segunda hoja
addWorksheet(wb, sheetName = "Frecuencias relativas")
# Escribimos la tabla en la segunda hoja
writeData(wb, sheet = "Frecuencias relativas", x = "Nivel educativo alcanzado por condición de completitud", startRow = 1)
writeData(wb, sheet = "Frecuencias relativas", x = tabla_educ,
borders = "rows" , borderStyle = "medium", startRow = 3)
# Guardamos el archivo
saveWorkbook(wb, "resultados/tablas_educativas.xlsx", overwrite = TRUE)Como se ve, el archivo ahora tiene dos hojas, y en cada una de ellas encontramos las tablas que exportamos desde RStudio.
3.2 Exportando a docx
Otra de las situaciones en la que nos podemos encontrar es ante la necesidad de exportar las tablas realizadas directamente a un archivo .docx en donde luego escribiremos texto. Para ello, utilizaremos la librería flextable, que nos permite no solo exportar las tablas, sino editarlas para que queden en un formato amigable para reportes, documentos, papers, etc.
Nuevamente, esta librería funciona en formato tidy y permite el uso de pipes. Lo primero que vamos a hacer es tomar el objeto tabla_educ que creamos anteriormente y exportarlo a un archivo .docx. Para esto, utilizaremos primero la función flextable() para convertir la tabla en un objeto de tipo flextable.
library(flextable)
flextable(tabla_educ)p09 | Completó | No completó |
|---|---|---|
Primario | 47.6% | 52.4% |
EGB | 6.7% | 93.3% |
Secundario | 47.1% | 52.9% |
Polimodal | 15.4% | 84.6% |
Sup. no universitario | 56.5% | 43.5% |
Universitario | 41.5% | 58.5% |
Posgrado | 65.4% | 34.6% |
Total | 41.9% | 58.1% |
La librería incluye muchísimas funciones para editar y automatizar el formato de salida de las tablas. Por ejemplo, podemos cambiar el formato de las celdas, agregar títulos, subtítulos, notas al pie, entre otras cosas.
Recomendación
Recomendamos revisar la página de la librería flextable para conocer las potencialidades que provee.
Vamos a probar ahora agregar en la primera columna la etiqueta de la variable p09 y en en una fila superior la etiqueta de la variable p10. Exploraremos algunas opciones de la función como set_header_labels(), add_header_row(), add_footer_lines(), set_caption(), theme_vanilla() y autofit(). El resultado lo guardaremos en un objeto llamado tabla_educ.
tabla_doc <- flextable(tabla_educ) %>%
set_header_labels(p09 = "Nivel educativo alcanzado") %>% # coloco la etiqueta de la variable p09 en la primera columna
add_header_row(values = c("", "Condición de completitud"), colwidths = c(1,2)) %>% # coloco la etiqueta de la variable p10 en una fila superior
add_footer_lines(values = c("Fuente: Censo Nacional de Población, Hogares y Viviendas 2010")) %>% # agrego una nota al pie
set_caption("Nivel educativo alcanzado por condición de completitud. Argentina, 2010") %>% # agrego un título a la tabla
theme_vanilla() %>% # cambio el tema de la tabla
autofit() # ajusto el ancho de las columnas automáticamente
tabla_docCondición de completitud | ||
|---|---|---|
Nivel educativo alcanzado | Completó | No completó |
Primario | 47.6% | 52.4% |
EGB | 6.7% | 93.3% |
Secundario | 47.1% | 52.9% |
Polimodal | 15.4% | 84.6% |
Sup. no universitario | 56.5% | 43.5% |
Universitario | 41.5% | 58.5% |
Posgrado | 65.4% | 34.6% |
Total | 41.9% | 58.1% |
Fuente: Censo Nacional de Población, Hogares y Viviendas 2010 | ||
Finalmente, para exportar la tabla a un archivo .docx, utilizaremos la función save_as_docx(), asignándole la carpeta donde queremos guardar el archivo y el nombre del mismo.
save_as_docx(tabla_doc, path = "resultados/tabla_educ.docx")